From Meshes to Splats: The New Language of Spatial AI
Spatial intelligence is older than language.
Long before humans drew symbols or shaped tools, we evolved the ability to form internal models of the world — imagining how a rock might slip underfoot, how a branch might bend, how an animal might move if startled. This capacity to simulate and anticipate is the foundation of physical reasoning and, arguably, of intelligence itself.
And for tens of thousands of years, humans have tried to externalize those inner worlds.
Cave drawings, Renaissance paintings, photography, cinematography, CAD software, modern game engines — each step brought us closer to projecting our internal models outward with increasing fidelity. A game designer today can invent a world and share it with billions, complete with physics, lighting, and interactive behavior. These synthetic worlds have even become training grounds for the next generation of intelligent agents, as seen in DeepMind’s SIMA 2 announcement, where robots learn to act and reason inside rich, simulated 3D environments.
Machines are now approaching their own version of this ability.
Modern Spatial-AI systems — and soon full-fledged Large World Models — learn geometry, materials, light, movement. They infer the structure behind images and videos, predict how scenes evolve, and reason about what lies outside the frame. But unlike humans, their spatial understanding is latent. Hidden inside learned weights.
For us to interact with that understanding — to inspect it, navigate it, test it, or simply see what the model believes — we need a representation.
A concrete, manipulable encoding of a 3D world that externalizes an AI’s internal hypotheses.
That representation must feel continuous.
It must carry the richness of real materials.
It must be efficient enough to run on everyday devices.
And it must be general enough to serve as a shared medium between humans and machines.
This is where the long evolution of digital 3D — from meshes to neural fields to splats — becomes central to the future of Spatial AI.
Long before humans drew symbols or shaped tools, we evolved the ability to form internal models of the world — imagining how a rock might slip underfoot, how a branch might bend, how an animal might move if startled. This capacity to simulate and anticipate is the foundation of physical reasoning and, arguably, of intelligence itself.
And for tens of thousands of years, humans have tried to externalize those inner worlds.
Cave drawings, Renaissance paintings, photography, cinematography, CAD software, modern game engines — each step brought us closer to projecting our internal models outward with increasing fidelity. A game designer today can invent a world and share it with billions, complete with physics, lighting, and interactive behavior. These synthetic worlds have even become training grounds for the next generation of intelligent agents, as seen in DeepMind’s SIMA 2 announcement, where robots learn to act and reason inside rich, simulated 3D environments.
Machines are now approaching their own version of this ability.
Modern Spatial-AI systems — and soon full-fledged Large World Models — learn geometry, materials, light, movement. They infer the structure behind images and videos, predict how scenes evolve, and reason about what lies outside the frame. But unlike humans, their spatial understanding is latent. Hidden inside learned weights.
For us to interact with that understanding — to inspect it, navigate it, test it, or simply see what the model believes — we need a representation.
A concrete, manipulable encoding of a 3D world that externalizes an AI’s internal hypotheses.
That representation must feel continuous.
It must carry the richness of real materials.
It must be efficient enough to run on everyday devices.
And it must be general enough to serve as a shared medium between humans and machines.
This is where the long evolution of digital 3D — from meshes to neural fields to splats — becomes central to the future of Spatial AI.
Meshes and Textures — The First Language of Digital Worlds
Before AI started reconstructing worlds from data, humans built them by hand. The backbone of that craft — for films, games, architecture, engineering — was the polygon mesh. Artists sculpted surfaces from triangles and quads, then wrapped them with texture maps that encoded color, fine detail, and sometimes even approximations of lighting. It was a remarkable achievement: a compact, GPU-friendly approximation of the physical world that could be rendered anywhere, from a movie pipeline to a PlayStation.
But meshes weren’t designed to be true representations of reality. They were designed to be workable illusions — efficient abstractions created for human consumption. Their surfaces are discretized, their materials painted, their lighting baked-in. They function beautifully for visual storytelling, where the goal is to be convincing rather than physically complete.
Seen through the eyes of a spatial-AI system, their limitations become obvious.
A mesh has no concept of uncertainty, no smooth gradients of geometry, no natural way to express how a material looks when light grazes it or reflects off it. A texture map is a static picture glued to a surface, blind to context, viewpoint, or time. Even advanced tricks like normal maps and shaders are ultimately patches on top of a fundamentally 2D illusion masquerading as 3D.
And perhaps most importantly:
meshes capture what humans can model — not what the world actually is.
They encode our handcrafted interpretation of surfaces, not the raw, continuous behavior of real materials and light.
Meshes excel at displaying worlds — at painting our imagination onto a screen.
But Spatial AI needs something different: a representation that is learned from data, that reflects the ambiguities of sensors, that respects the continuous nature of the physical world, and that can scale from real environments to imagined ones.
Traditional meshes were the first language of digital 3D.
But they were never meant to be the language of machine understanding.
But meshes weren’t designed to be true representations of reality. They were designed to be workable illusions — efficient abstractions created for human consumption. Their surfaces are discretized, their materials painted, their lighting baked-in. They function beautifully for visual storytelling, where the goal is to be convincing rather than physically complete.
Seen through the eyes of a spatial-AI system, their limitations become obvious.
A mesh has no concept of uncertainty, no smooth gradients of geometry, no natural way to express how a material looks when light grazes it or reflects off it. A texture map is a static picture glued to a surface, blind to context, viewpoint, or time. Even advanced tricks like normal maps and shaders are ultimately patches on top of a fundamentally 2D illusion masquerading as 3D.
And perhaps most importantly:
meshes capture what humans can model — not what the world actually is.
They encode our handcrafted interpretation of surfaces, not the raw, continuous behavior of real materials and light.
Meshes excel at displaying worlds — at painting our imagination onto a screen.
But Spatial AI needs something different: a representation that is learned from data, that reflects the ambiguities of sensors, that respects the continuous nature of the physical world, and that can scale from real environments to imagined ones.
Traditional meshes were the first language of digital 3D.
But they were never meant to be the language of machine understanding.
Neural Rendering — The World as a Function
The next leap arrived not from graphics engineers, but from machine learning. Neural Radiance Fields (NeRFs) changed the mindset entirely. Instead of explicitly modeling surfaces, NeRFs learned how a scene looks from data.
It was a profound shift: geometry, shading, and reflectance were no longer handcrafted—they were emergent. Reflections appeared naturally. The world felt continuous. For the first time, we had a representation that behaved like our own perception: it interpolated, generalized, and filled in the gaps.
But the breakthrough came with a catch. NeRFs were breathtakingly realistic, yet stubbornly impractical—slow to train and heavy to render. They raised a tantalizing question: Could we capture the richness of learned appearance while achieving the speed needed for interactive worlds?
Gaussian Splats — Fidelity Meets Efficiency
Gaussian Splatting arrived as the bridge between neural fidelity and classical speed. Instead of burying the world inside a black-box neural network, splats represent the scene as a cloud of tiny 3D Gaussians—soft, elliptical volumes that carry position, color, opacity, and view-dependent shading.
It turns out this simple idea is remarkably powerful. Gaussians blend seamlessly, preserving the soft edges and gloss of the real world, yet they render on GPUs as explicitly as triangles. The result is near-NeRF richness at real-time speeds.
This shift democratized capture. We moved from specialized scanners to a world where a modern smartphone can generate a faithful reconstruction. But for Spatial AI to truly use this medium, raw visual fidelity wasn't enough. The representation needed to mature.
Making the Illusion Tangible
Fidelity is worthless if it can’t be shared, and a world is useless if it doesn't push back. The recent evolution of Splats has focused on turning them from pretty pictures into robust infrastructure.
From Gigabytes to Streams
Early splat scenes were massive—gigabytes of raw data. 2025 changed the calculus. Innovations like Spatially Ordered Gaussians (SOG) and Niantic’s .spz format organized the chaos. By arranging Gaussians along spatial curves (Morton codes) and applying aggressive quantization, we can now stream detailed 3D worlds as easily as video.

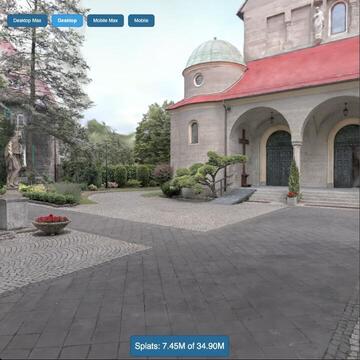
Adding the Sense of Touch
A visual stream isn't a world; it’s a ghost. A splat cloud has no native concept of a "wall" or "floor"—it is merely density. To support agents, we are seeing a shift toward hybrid representations: splats for the rich, high-frequency visual signal, layered over lightweight collision proxies or voxels for physics. This combination allows a robot to see the texture of a rug but feel the solidity of the floor beneath it.

Learning from the Wild
Perhaps most importantly, this robust format allows AI to leave the lab. New techniques like WildGaussians and Scaffold-GS can ingest messy, crowd-sourced internet photos—ignoring moving cars and tourists—to reconstruct coherent, static worlds.We can now turn the visual noise of the internet into structured, navigable environments. This provides the "playground" for the next phase of AI: Generation.

Robust Neural Rendering in the Wild with Asymmetric Dual 3D Gaussian Splatting
(NeurIPS 2025 Spotlight)
Spatial-AI Generation — When Models Reveal Their Inner Worlds
If reconstruction shows how machines recover the world, generation shows how they imagine it. We are seeing a wave of models that take sparse input—a photo or a text prompt—and expand it into a fully navigable splat scene.These are the early signs of AI systems revealing the worlds they carry in their heads.
- Navigable Invention: Tools like Marble from World Labs go further, generating new geometry and viewpoints far beyond the original frame, allowing users to explore a place that never existed.
- Simulation & Action: DeepMind’s Genie (and its successors) moves beyond rendering to simulation. Characters can climb, fall, and interact. The system behaves as if it has learned the rules of a world, not just its pixels.
These models are effectively saying: "Given this sparse input, here is the world I believe could exist."

A Shared Language for Spatial Intelligence
We opened with the idea that humans express their internal models through art and stories. Spatial-AI systems are beginning to form their own internal worlds, but those worlds are invisible unless we give them a language.
That language is the representation.
Meshes were our first vocabulary. Neural fields expanded what could be expressed. Gaussian splats—now compressed, streamable, and physically grounded—are the first medium flexible enough to bridge both sides.
What matters isn't just that splats look pretty. What matters is that they allow an AI to externalize a belief.
For reconstruction models, splats are a hypothesis about reality.For generative world models, splats are the canvas of imagination.
For future Large World Models, splats may become the medium through which agents communicate spatial understanding with us—and with each other.
As sensors, models, and runtime engines converge, we are moving toward systems that not only reason in 3D but can reconstruct, invent, and share their internal worlds as fluidly as humans sketch ours.
Gaussian splats just happen to be the first language that everyone—human and machine—can finally speak.